| GISdevelopment.net ---> AARS ---> ACRS 2002 ---> Land Use/Land Cover |
Regional land cover mapping
of the Hindu Kush-Himalayan using satellite image: An approach to
understand the dynamics of land use and land cover change
Sushil
Pradhan
Mountain Environment and Natural Resources Information Systems (MENRIS)
International Centre for Integrated Mountain Development (ICIMOD)
G.P.O. Box 3226, Kathmandu, Nepal
Tel.: 977-1-525313
Fax: 977-1-524509
E-mail: sushil@icimod.org.np
Mountain Environment and Natural Resources Information Systems (MENRIS)
International Centre for Integrated Mountain Development (ICIMOD)
G.P.O. Box 3226, Kathmandu, Nepal
Tel.: 977-1-525313
Fax: 977-1-524509
E-mail: sushil@icimod.org.np
Abstract
During the past few decades, mountain areas throughout the Hindu Kush-Himalayan (HKH) region have experienced rapid change. Expansion in education and health services, the development of roads and electricity, improvements in irrigation and agricultural and related technologies, and the penetration of commercial forces are drastically affecting land cover and ecosystems of many parts of the mountain areas. Each of these factors contributes with varying degree to the change dynamics of mountain areas. A contributory factor may be applicable in one area, but not in another. It is therefore important to study and understand the dynamics of land use and land cover change and determine which factor contributes significantly in a specific area before proper land use planning can be done. This process, first, required a standard methodology to understand and explain the pattern of land cover of the region. With this concept, ICIMOD formulated and initiated a project for land cover mapping of the region in 1999. A methodological study for the land cover mapping of the region has been carried out and developed. The methodology, which is based on GIS and remote sensing (RS), has been tested for the land cover mapping of Bhutan and Nepal using IRS-WiFs data. The study mainly focused on how to generate reliable and good training samples, those are spectrally homogenous and spatially significant, for the accurate classification of the image. The study also integrated other information, e.g. DEM (Digital Elevation Model), rainfall, and temperature, with the land cover map classified from the image for the detailed forest type classification. Accuracy assessment of the result was done to validate the methodology and showed a satisfactory accuracy of 83 and 88 percent for Bhutan and Nepal, respectively.
Introduction
The global environmental change community has increasingly recognised the significance of land-use and land-cover change and the need for an interdisciplinary research approach to the subject, basically in improving our basic understanding of the dynamics of Land-Use and Land-Cover Change globally, with a focus on improving our ability to model and project such change..The Hindu Kush-Himalayan (HKH) (Figure 1) is the mandated area of ICIMOD covering eight regional member countries: Afghanistan, Bangladesh, Bhutan, China, India, Myanmar, Nepal, and Pakistan. The HKH region contains world’s highest, largest, and most populated mountain systems. ICIMOD has great challenge in maintaining environmental degradation and managing natural resources of the region for the beneficial of mountain peoples. During the past few decades, mountain areas throughout the region have experienced rapid change. Soil erosion, deforestation, landslides, land degradation, and water resources are common problems of the region. Expansion in education and health services, the development of roads and electricity, improvements in irrigation and agricultural and related technologies, and the penetration of commercial forces are drastically affecting land cover and ecosystems of many parts of the mountain areas. Each of these factors contributes with varying degree to the change dynamics of mountain areas.
A contributory factor may be applicable in one area, but not in another. It is therefore important to study and understand the dynamics of land use and land cover change of the region and to determine which factor contributes significantly in a specific area before proper land use planning can be done. With this knowledge, policy makers and planners will be able to predict the availability of food and other natural resources for the coming years. Land use/land cover change study is a diagnostic tool for determining sustainability and is therefore important that this tool can be done carefully and properly for the sustainable development of the HKH region.
To study the land use and land cover dynamics of the region, the linking of social and biophysical information with spatial component is important. In other hand, there is increased interest today in making scientific progress through use of remotely sensed data in social science research, i.e. linking people and pixels. Remotely sensed data have potential value for the study of human-environment interactions, especially land-cover and land-use change, and it also have potential scientific value for addressing questions in other areas of social science, including human population dynamics.
Objectives
The primary goal of the project is to understand the dynamics of land use and land cover change in mountain ecosystems of the HKH region. To meet this primary goal, an initial study has been carried out, which is the main focus of this paper, with the main objective as follow:
- Develop a standard methodology to understand and explain the pattern of land cover characterization of the region using satellite images.
- To investigate the spectral information content of different land cover types to generate spectrally homogenous and spatially significant training samples;
- To study to improve the land cover classification using knowledge-based rules, topographic factors, and higher remotely sensed data;
- To study to produce detailed forest types classification; and
- To assess the accuracy to validate the proposed methodology.
The study used the IRS WiFs (Wide Field Sensor) satellite data. The WiFs satellite data has two bands – Red and Near Infrared (NIR), with spatial resolution 188.3m. The project acquired the WiFs satellite data between the periods of 1996-1999 covering the whole HKH region. The study also used other ancillary data, DEM (Digital Elevation Model), rainfall and temperature data to meet the main objective.
Methodology
The study acquired 12 scenes of the WiFs satellite data covering the whole HKH region. Each of these scenes were rectified and geometrically corrected using ground control points (GCPs) from defense mapping agency aerospace center (DMAAC), Missouri, USA. All the GCPs were verified in the Operational Navigation Chart (ONC) of scale 1:1000,000, and the same location were identified on the images and registered using Erdas Imagine 8.4 software. Overall root mean square error (RMS) was limited within a pixel. Then it was resampled to pixel size 180m x 180m. Resampling was done using nearest neighborhood method, which maintains the original DN of pixels.
The images were projected into Albers Conical Equal Area with WGS84 spheroid and datum. After geo-referencing, all the images were combined (mosaic) into a single image as shown in Figure 2.

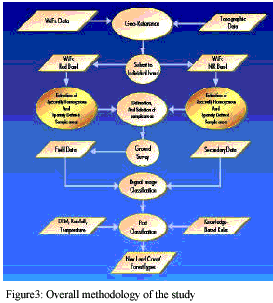
After geo-referencing and mosaicking of the images, the images were subset to individual band. From each band, the training samples were generated. Remote sensing technology sounds very interesting and is useful, but its quality highly depends on the quality of training samples. It requires good training samples for the accurate image classification. Good training sample means – it should be spectrally homogenous and spatially large enough. It’s very critical process to select good training samples for the accurate image classification. So, the main theme of this study is how can we generate good training samples, i.e. spectrally homogenous and spatially significant, for the image classification. Because of the limitation of our human eye, we can’t distinguish the spectral homogeneity of the pixels. Therefore, an algorithm was used to extract the spectrally homogenous pixel groups (Figure 4).
To generate spectrally significant and spatially homogenous training samples, following steps were carried out:
- Derived all the possible spectral groups of pixels of Red and near
infrared (NIR) bands that are within the specific range of values, e.g.
5. The pixels having 0 histograms were omitted while selecting. The
pixels within the defined ranges were recoded to unique values.
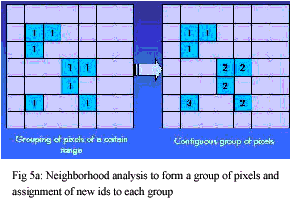
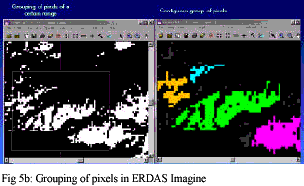
- The pixels belonging to same contiguous groups were grouped and given unique identifier(Fig 5a & 5b)
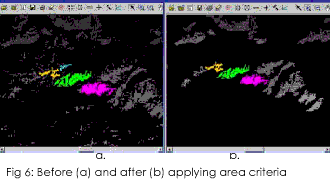
- The appeared salt and pepper pixels were eliminated by definig area
criteria (Fig 6a & 6b). A threshold of 50 pizels, i.e.
1.62KM2 was defined to obtain spatially homogenous training
samples. The group of pixel was again recoded to an integer identifier
of particular spectral class. These samples were used as the basic units
for regional reviews and legends for land use land cover mapping which
indicate the basic spatial unit.
- Number of Area of Interest (AOI) was created from each spatial unit in each band (Fig 7). While creating AOI, standard deviation was maintained within the limit of less than or equal to 2.0 in each class.
- After delineating AOI from Red and NIR band, they were merged together as a single file.
- After merging the AOIs, statistical report was derived. The homogeneity of training samples was measured by means of standard deviation (þ), which can be viewed as providing the a measure of the uncertainty. So, higher the þ, there will be more uncertainty. Low þ of a set of data values indicates how similar enough they are. The classes having highest frequency numbers of pixels in order and low ? are selected as the final training samples for the land cover types identification. The spectral range, standard deviation (þ) and land cover are illustrated in Table 1.
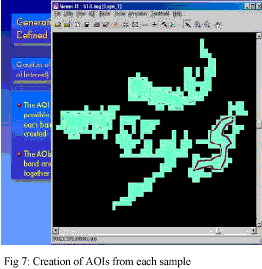
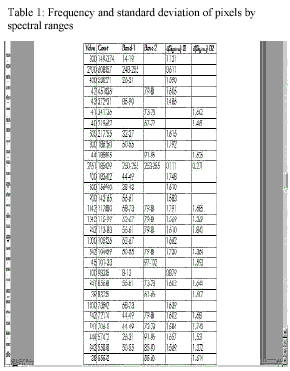
Image Classification
Thus generated spectrally homogenous and spatially significant training samples are the basic spatial units for ground truth and primary data collection for the image classification.
Case of Nepal
The WiFs satellite data was first subset based on the international boundary of Nepal (Fig 8). Using the methodology (refer to Fig.3) as described above, spectrally homogenous and spatially significant training samples were generated.

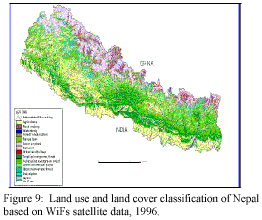
The field visit was carried out to verify the land use and land cover types in each of these training samples. In this process, the existing land use and land cover data (LRMP 1978/79) of Nepal was used as reference. Then the image was classified using these ground truth data (Fig. 9) and the standard land use/land cover classification scheme was maintained while classification the image.
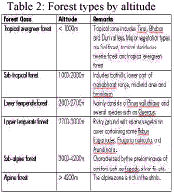
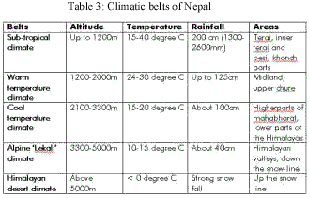
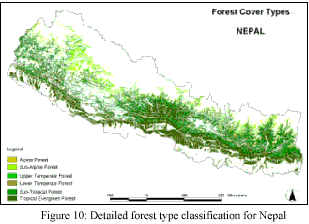
For the detailed forest types classification, the information on forest types by altitude (Table 2), and temperature and rainfall data at different altitudes of Nepal (Table 3) were collected. These information were integrated with a DEM (Digital Elevation Model) and the newly classified land use and land cover data for the detailed forest type classification (Fig. 10).
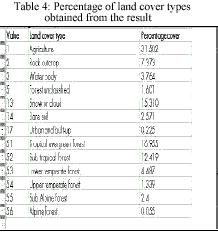
About 10% of the total sample areas were randomly selected for the accuracy assessment. The overall accuracy assessment of the result was 88%.
Case of Bhutan
Similarly, the image for Bhutan was subset (Fig. 11) and the spectrally homogenous and spatially defined training samples were generated for the ground truth data collection.
But due to various reasons, no field visit was carried out. The Ministry of Agriculture of Royal Government of Bhutan provided the digital version of land use and land cover data of 1994, which was produced using Landsat-TM data with thorough field verification. Assuming that there would not much difference in land cover within two years in mountainous country like Bhutan, the provided digital land cover data of 1994 was used as the reference for image classification. For this,
- The existing land cover data of 1994, was rasterized using 180m x 180m pixel size (same as of WiFs). Unique cell value was assigned to different land cover types.
- The abovegenerated training samples were rasterized using the same pixel size. The cell value 1 was given to all.
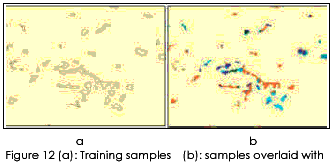
- The rasterized training samples (2) was overlaid with 1994 land cover data (1). It resulted the training samples with certain land cover codes as of 1994. Different types of land cover within an AOI are identified (which is the main purpose of field visit) (Figure 12a & 12b).
- The resulted samples (3) with different land cover codes was
converted to Imagine format and used for classifying the image. The
maximum likelihood method was applied for classification.

Classified data often manifest a salt-and-pepper appearance due to the inherent spectral variability encountered by a classifier when applied on a pixel-by-pixel basis (Lillesand and Kiefer, 1994). The 3-by-3-majority filter was applied to remove salt-and-pepper appearance.
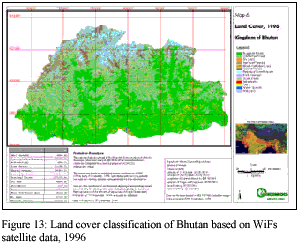
Post classification of the classified image was mainly required due to existence of cloud cover. Due to the lack of mid infra-red and thermal infra-red channels in Wifs data, there was mis-classification between cloud and snow. The area covered by clouds were masked with null values by screen digitization, and later, neighbourhood classification of the masked area (null values) was done. The whole classified image and the classes under clouds was improved by applying knowledge-based rules, taking the land cover data of 1994 as reference. The final classified map is presented in Fig. 13.
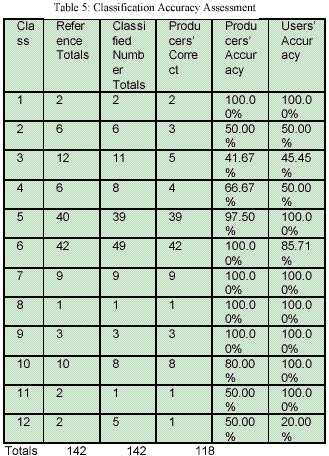
Accuracy assessment of the classified image was done with 143 randomly selected points. For this purpose, the land cover data of 1994 was taken as the reference. The overall accuracy of the classified image is 83.10%. The details of the accuracy report are given below in Table 5.
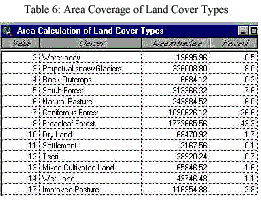
From the analysis, broadleaf forest and coniferous forest has been found as the dominant land cover classes, which is 43.3 and 26.6 percent, respectively. The coverage area of different land cover classes and their percentage are given below in Table 6.
Limitations
- Due to the coarse spatial resolution of WiFs data (80m x 80m), there was limitation in the detail discrimination of different land use and land cover types. However, the improvement of classification by applying knowledge-based rule was helpful in classifying different types of agricultural land and settlements.
- Due to the absence of mid-infrared and thermal band within the WiFs data, the separation of cloud and snow was not possible, which was also improved by post-classification.
The study mainly focused on generating spectrally homogenous and spatially significant sample areas for the classification of a satellite image. Thus generated training samples are statistically un-biased and are basic units for the ground truth data collection. The field visit is very essential and the field data should be very accurate as the classification highly depends on it. While generating training samples, the sample areas may exist anywhere or any part of the country. So, the question may arise – is it possible to visit each and every or most of the sample areas in the mountainous countries within HKH where the infrastructures are very poor? This is a big question and therefore needs further discussion to come up with a certain agreement
Of course, it would be better if we use medium resolution multi-spectral satellite data, e.g. LandSat-TM (30m), for the identification of different agricultural land use types and forest types. There is no doubt that it would produce more accurate result, but the question is about the cost, which is about 20 times expensive than using the IRS-WiFs satellite data. Therefore, WiFs data is good enough to be incorporated with the proposed methodology for a regional or national level study. The methodology will work well and is recommended to use at a watershed level using medium or higher resolution satellite data.
Reference:
- The Global Environmental Change and Human Securities (GECHS), http://www.gechs.org/
- Global change SysTem for Analysis, Research, and Training – START, http://www.start.org/
- Land Use and Land Cover Change – LUCC, http://www/geo.ucl.ac.be/LUCC/lucc.html
- International Geosphere-Biosphere Programme (IGBP), http://www.igbp.kva.se/cgi-bin/php
- International Human Dimensions Programme on Global Environmental Change (IHDP), http://www.uni-bonn.de/ihdp
- People and Pixels – linking remote sensing and social science, National Academy Press, Washington, DC, USA, 1998.
- International Centre for Integrated Mountain Development (ICIMOD), http://www.icimod.org.np/
- Pradhan, S.: Progress report on land cover classification of Bhutan using IRS-WiFs satellite data, MENRIS / ICIMOD,2000.