| GISdevelopment.net ---> AARS ---> ACRS 2002 ---> Data Processing, Algorithm and Modelling |
PC clusters as a platform for
image processing: promises and pitfalls
Kurt T.
Rudahl
Goldin-Rudahl Systems, Inc.
#213; 6 University Drive Suite 206
Amherst MA 01002, U.S.A.
Email: ktr@goldin-rudahl.com
Website: http://www.goldin-rudahl.com/
Sally E. Goldin
Goldin-Rudahl Systems, Inc.
#213; 6 University Drive Suite 206
Amherst MA 01002, U.S.A.
Website: http://www.goldin-rudahl.com/
Goldin-Rudahl Systems, Inc.
#213; 6 University Drive Suite 206
Amherst MA 01002, U.S.A.
Email: ktr@goldin-rudahl.com
Website: http://www.goldin-rudahl.com/
Sally E. Goldin
Goldin-Rudahl Systems, Inc.
#213; 6 University Drive Suite 206
Amherst MA 01002, U.S.A.
Website: http://www.goldin-rudahl.com/
Abstract
The growing acceptance and maturity of "desktop supercomputers" consisting of clusters of inexpensive personal computers brings unlimited image processing capability within the reach of all. Clusters can be composed of whatever miscellaneous computers are available. New units can be added without discarding the old, and specialized capabilities residing on only a minority of the computers can be utilized optimally. However, the technical skills required to configure PC clusters remain an obstacle to their widespread adoption. This paper provides an overview of fundamental cluster concepts and introduces a "plug-and-play" cluster implementation designed for use with the Dragon Image Processing System.
Introduction
Remote sensing and GIS are characterized by a need to perform computationally-intensive operations on large data sets. Full-scene image processing requires operating on tens of millions of image data points per scene, while GIS operations such as viewshed analysis or calculating optimal routes may involve evaluation of candidate solutions whose number increases exponentially with the spatial extent of the problem area.
The desktop personal computer has grown from a curiosity to become the norm for much of the world's computing. Today, it offers the lowest cost, on a dollars per floating-point operation basis, of any computing architecture. Nevertheless, it still can be inadequate for the most demanding tasks. The difficulty is not a shortage of memory or disk storage, nor is it (in all cases) a lack of suitable software. The problem is one of elapsed time. A program which takes hours, days, or weeks to execute is simply too slow to be useful.
The simple answer, of course, is to use a faster computer. However, once one moves beyond the realm of the personal computer to specialized workstations or mainframes, the price can go up much more rapidly than the performance.
An attractive alternative, which we examine in this paper, is to group and coordinate a collection, or cluster, of inexpensive PC's to cooperatively perform the computation. Ideally, the cost of this approach should be directly proportional to the desired speedup (although in practice this ideal cannot be achieved completely). Other advantages such as ease of procurement and maintenance, and the possible ability to reuse existing software, are apparent.
Understanding the problem: Some examples
To put the above into perspective, let us offer some concrete examples. The numbers cited are not too important; your computers may be faster or slower than ours. It is the comparisons that are important..The First Example Let's say that I have just bought the fastest, newest PC that I could get. Let's say that I have a collection of old music (perhaps 1000 pieces) that I want to convert into MPEG format so I can play them while I'm mountain climbing. However, I rapidly discover that each piece (representing one phonograph record) takes my computer about half an hour to convert. All told, I'm going to be running that computer full-time, 24 hours per day, for most of a month to convert all that music.
We Westerners are not a patient lot, so what can I do to speed things up? I've already got the fastest PC available. I can't really afford a Silicon Graphics workstation or IBM mainframe, and even if I could, it probably wouldn't support my software.
However, if I could just put two or three PC's to work on it, I could (in principle) get it done in a week. Twenty PC's would get it down to a day. (What's the price of twenty PC's compared to a mainframe? I'm not sure, but I'll bet the PC's would be cheaper.) Taking this a step further: suppose that I do purchase a dozen new PC's for this purpose. My results are so impressive that my friends start coming to me with requests to do these audio conversions for them. Now, even all my computers together are too slow. However, I can just go buy some more. The old ones aren't wasted; they're just added into the pile.
A Second Example
Moving into the remote-sensing domain, let's assume that I am doing an astronomy study on some remote galaxies. Because the light is so faint, I need to extensively pre-process each image. In order to minimize the chance of getting bad results and having to repeat the measurements, I want to process the images as they're being received from the sensor. In effect, I want to complete the processing on one image before starting the next.
Let's assume that I acquire a new image every ten minutes, but processing an image on a single computer requires an hour. The problem, then, is that I have a single task which takes six times longer than the time window in which I have to accomplish it. If I can distribute the processing burden of this task across six (or, to be safe, seven or eight) PC's, I can solve this problem.
Basic Architecture
The notion of obtaining high-powered computing capabilities based on inexpensive PC's congealed somewhere during the late 1990's, in various U.S. universities and government labs, into the Beowulf architecture (Sterling et al., 1999). Since that time, use of this architecture has spread around the world, so that today several of the world's fastest "supercomputers" are actually large Beowulf clusters. In fact, there are other possible architectures for a PC cluster; Beowulf just happens to be the easiest and least expensive.
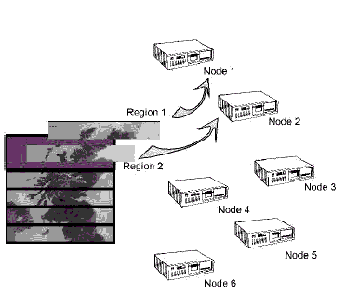
Figure 1: Basic Cluster Architecture
The Hardware
The basic design objective of a Beowulf is that it should use only mass produced, commonly available hardware and software. Thus the hardware, as shown in the illustration, is usually standard PC's connected by high-speed ethernet. (Of course, the cheapest computers are those you already own, so if you happen to have a bunch of Sparc's or Macintosh Unix machines, those would be fine.) Traditionally high-speed ethernet switches have been fairly expensive, but prices are coming down rapidly and, in any case, you only need one of them.
The PC's, or nodes, do not have to be all the same, either in hardware or operating system, although system administration can get to be a headache if they're very different. Generally, the software which needs to be executed is installed in advance on each node to avoid the delays of loading across the network.
One of the nodes is special, as shown, in that it connects both to the cluster and to the "outside world". This double-headed node acts as a firewall: it filters and controls all data arriving from the outside. This allows the other nodes to run with all security restrictions turned off. The double-headed node also frequently handles administration, status monitoring, and other chores.
We should emphasize that, despite the term "high speed ethernet", the use of ethernet for communication is actually the slowest part of the system. Its major virtue is that it is much less expensive (both in money and effort) than the next best choice. However, this fact imposes some constraints on what types of problems are suitable for Beowulf processing. The good news is that there are still many suitable computational tasks in remote sensing and GIS.
The Operating System
There are a number of possible operating systems available, but Linux is almost always the final choice. There are several reasons for this:
- Linux is free. This is a strong argument, although Linux is not the only free OS.
- Linux runs on most processor types that you might want to use, including Intel, Alpha, Sparc, and PowerPC. In fact, Linux was the first operating system available for the Itanium IA-64.
- There is a variety of special software and knowledge available for Linux from the various Beowulf projects, particularly in the area of optimized network drivers.
- Linux is well known. Since Linux is essentially Unix, many people have experience working with it. Of course, especially in an organization which is not particularly computer-science-oriented, Unix expertise is not as common as Windows expertise. Nevertheless, the other considerations listed usually rule out a Windows -based approach.
- Finally, as discussed below in more detail, the typical Unix style of software, based on independent tools and utilities, make it particularly easy to use already-existing applications and components.
The Software
Not every computing task or algorithm is appropriate for a cluster. A task may not be parallelizable because its essential nature requires that each step be completed before the next step is begun; there is no work that can accomplished in parallel by multiple processors. It is also possible that a task might be parallelizable but not appropriate to the slow Beowulf communication.
The most common question, however, assuming you are not planning to develop the software yourself, is whether the software you actually have available can be used in a parallel fashion. In essence, software that is parallelizable needs to consist of separate components which can run semi-independently on each node in the cluster, plus software to coordinate the different processes and partial results. (Semi-independently means, among other things, that the components should not require much user interaction.)
In some cases, you may be able to find software (such as our Parallel Dragon) which includes all the necessary components together. However, you can also create your own parallel system using available processing modules and script-based coordination. Alternatively, if you have the source code for a software package, you may be able to parallelize it yourself, or hire a consultant to do it.
Multiple Simultaneous computations with process-level parallelism
There is an important difference between the two examples described earlier. In the first example, the only concern was throughput. Each computer was operating independently, converting one single disk file (a piece of music) into one new disk file. It did not matter when each file got finished, only that the full set of them should completed as soon as possible. Thus, coordination among the computers was the only issue.
The task in the second example was more difficult (and accordingly more interesting). In that case, a single task was to be completed more quickly by using multiple computers. The need, therefore, was to be able to break that single task apart, somehow, and then eventually to reassemble the pieces in a useful way.
The first example is an illustration of process-level parallelism (or what is sometimes called an embarrassingly parallel task). (We use the term process to refer to a single indivisible executable such as a Windows .EXE file, which accomplishes a single objective.) This type of parallelism requires:
- Some already existing program which can perform one instance of an
operation (such as compressing music to MPEG format) which you need done
multiple times, and which can be run without user intervention (i.e. can
be given its input parameters on the command line, in a file, or in some
other non-interactive way). Notice that this is exactly the same program
that you would run on a single computer, without modifications. You
don't need to write the program, rewrite the program, have the source
code, or even know anything about how the program does its job. (You do,
of course, need a license to run it on multiple computers.)
- A program or script which can distribute the particular parameters
for each instance out to the cluster nodes, and (possibly) collect the
results when done.
This control/administrative program does need to know about your cluster, but it does not need to know anything about the nature of the task you are trying to accomplish. Therefore this program is the added value which you, or somebody, must supply in order for your cluster to function.
rsh node1.mycluster.myhome.edu bladeenc Stones_LetItBleed.wav
rsh node2.mycluster.myhome.edu bladeenc Beatles_Revolver.wav
rsh node3.mycluster.myhome.edu bladeenc RaviShankar_Duets.wav
(This is a script which invokes the Linux rsh utility to run the bladeenc music conversion program on different computers, using different input files).
A more general solution would be able to adapt to different kinds of tasks and to different and changing cluster configurations, and would provide administrative, job control, and status reporting capabilities. The PVM (standing for Parallel Virtual Machine) package (Geist et al., 1997) provides one approach and set of facilities for creating such control programs. Perl also has such capabilities available. Given an adequately sophisticated control and administration paradigm, process level parallelism can be extended beyond simple multiple execution of independent instances, to include various pipeline and dataflow tasks. The only requirement would be that each pipeline or dataflow stage be capable of being executed as a stand-alone process. However, this is too complex a topic to consider in detail here.
Partitioning a single process for parallel execution
Process-level parallelism cannot be applied to all types of tasks you might want to distribute across a cluster. One important category, illustrated by the second example above, involves a task where external constraints require that a single instance of a single process execute faster than it can on a single computer.
At this point we can no longer ignore the question of what the process does and how it does it. In fact, we need to have the source code, and to be prepared to rewrite some of it. In essence, it is necessary to restructure the process so that it becomes several pieces which can be run on separate computers. It may well be that these parts will need to communicate among themselves while executing, so a cross-machine interprocess communication mechanism is also needed.
Figure 2: Partitioning an image processing task across nodes
(You may want to restructure the software yourself, or to buy revised software from someone who has already gone through the process, or to contract someone to do the rewrite for you. Obviously, licensing considerations are important.)
We will not try to explain the restructuring process in detail here. If the software you want to partition was created at your lab, partitioning may be easy. Otherwise it may be difficult or even (if you don't have the source code) impossible. However, the second example, illustrated in Figure 2, shows well why we contend that cluster processing is very appropriate to remote sensing.
The objective is to do some sort of time-consuming computations, which we have not specified, to a remote sensing image. From a computational perspective, any remote -sensing image is the image of a.fragment of the landscape (or skyscape, seascape, etc.) with arbitrary boundaries. Usually, though not always, the computational properties are unchanged if we work separately with fragments of that fragment, and then recombine the partial results.
The illustration depicts subdividing the image into six regions, each to be processed on one node of a six-node cluster. There is nothing magical about either the number or the shape of regions, or the number of cluster nodes. An important question, however, is the detailed mathematical properties of the computational algorithm. If each pixel is computed independently of the values of adjacent pixels, then each region can be processed separately and there may be no need to revise the core program at all. (You just need to subdivide and then reassemble the image.) However, if computations for one region must consider information about other regions, then mechanisms must be available for communicating that information in a timely and efficient manner between cluster nodes. A commonly used facility for this is the Message Passing Interface (MPI) (Snir et al., 1999).
Moving form the Lab to the real world: Designs for dragon/IPS
Traditionally, PC clusters have been to a large extent laboratory animals. They have been created one at a time, frequently by the same group which will ultimately be using them. Thus, their users tend to be familiar with their innards and able to adapt to changing configuration and support software. As the economic and performance benefits of the Beowulf architecture become better known, there is a growing demand to move clusters from an experimental into a production status. The PC-based computer nodes themselves are familiar and widely available, as are (to a somewhat lesser extent) the network and operating system components. However, specialized clustering software, at a level appropriate to the intended user community, also needs to be available.
Goldin-Rudahl Systems, Inc. has been making and selling the Dragon/ips þ remote-sensing package for many years, as well as providing software consulting services. As of the current release of Dragon, we have no need for cluster computing. Dragon is quite fast enough on a single computer, in part because we do not currently support any particularly time-consuming image processing algorithms.
As we look to a future of very large images, hyperspectral images, real-time processing, and algorithms such as neural network and genetic processing, we can see our needs outstripping single-machine capabilities. PC clusters appear to be an inevitable answer to this need. However, we have to recognize that our customers are not computer science research labs; they are remote sensing and GIS labs. We anticipate that we will need to provide, one way or another, solutions for the following cluster-specific software requirements:
- Application software. Dragon is already running on Linux at the
process level. New image processing and GIS algorithms, as they are
developed, will be designed for parallel execution. We will also create,
on special order, custom image processing or GIS modules. For the lab
which is already running a Beowulf, this will be sufficient. However, we
feel that we also need to adapt to the needs of a "novice" lab.
Therefore, we are developing: <>LI>Installation software. It
should not be necessary for the person installing and maintaining a
cluster to be a Unix guru. We will provide a "plug-and-play"
installation kit. The traditional Unix installation philosophy is that
an installation program can be wrong, broken, and undocumented because
the user is an expert at reading system logs, knows every detail of her
computer, is familiar with every known Unix utility back to the
beginning of time, and can deal with any unusual circumstance which
might arise.
The traditional Windows installation philosophy is that the user knows absolutely nothing, but since nothing can possibly go wrong, there's no need to give her any meaningful instruction, choices, or error recovery possibilities.
We plan to combine the best of these two philosophies by providing a simple, automated process, with adequate mechanisms and documentation to support likely customizations or trouble shooting. - Task management software. The concept of a cluster is defeated if
the user needs to specify in detail what gets executed where and when.
On the other hand, you are wasting your money if tasks are not allocated
efficiently to available computing resources.
The approach taken by most of the popular task management systems, such as PVM (Geist et al., 1997), is essentially top-down, with an executive that distributes processes to nodes based on.various policies or heuristics. At Goldin-Rudahl Systems we are using a different approach based on the language Linda (Carriero & Gelertner, 1989), in which the allocation of work is self-organizing and involves all nodes.
- Status monitoring software. It can be surprisingly difficult to notice, in a cluster, that one of your computers has stopped working altogether, especially if you never really intended to give up on remote sensing research to devote yourself full-time to system administration. We are working on simple and intuitive tools for monitoring cluster status.
The configuration discussed here is commonly referred to as a Beowulf cluster or desktop supercomputer or pile-of-PC's. Active research in architecture and tools is ongoing in numerous locations around the world. Here in Asia, for example, Dr. Putchong Uthayopas (Uthayopas, 2001) at Kasetsart University in Bangkok has done extensive work on the administrative and status monitoring aspects of cluster execution.
Because of the nature of remote sensing and GIS algorithms, which can often be decomposed spatially or along other dimensions, these processes are excellent candidates for execution in a cluster environment. The amount of geospatial data being gathered is growing at an extreme, indeed almost frightening, rate. Beowulf clusters provide one potential solution for extracting vital information from these masses of data in a timely and cost-effective way.
Problems remain, however. Setting up a cluster computer may not be a trivial effort. As a commercial vendor of remote sensing solutions, our company is interested in resolving these problems so that specialis ts in fields quite outside of computer science, who do not wish to trouble themselves with becoming Unix gurus, can gain the benefit of using this technology.
References
- Carriero, N. & Gelertner, D., 1989. Linda in Context. Communications of the ACM, April 1989, Vol.32, No.4, pp 444-458.
- Geist, A.., Beguelin, A.., Dongarra, J., Jiang, W., Manchek, R., & Sunderam, V., 1997. PVM Parallel Virtual Machine: A Users’ Guide for Networked Parallel Computing. MIT Press, Cambridge, Massachusetts.
- Snir, M., Otto, S., Huss-Lederman, S., Walker, D. & Dongarra, J., 1999. MPI – The Complete Reference. MIT Press, Cambridge, Massachusetts. Sterling, T., Salmon, J., Becker, D. & Savarese, D., 1999. How to Build a Beowulf. MIT Press, Cambridge, Massachusetts.
- Uthayopas, P., 2001. Building a Resources Monitoring System for SMILE Beowulf Cluster. Kasetsart University, Bangkok, Thailand. http://prg.cpe.ku.ac.th/publications/hpcasia.pdf