| GISdevelopment.net ---> AARS ---> ACRS 2000 ---> Image processing |
Parallel Computing in Remote
Sensing Data Processing
Chao-Tung Yang *Chi-Chu Hung
Associate Researcher Satellite Analyst
Ground System Section
National Space Program Office
Hsinchu, Taiwan
Tel:+886-3-5784208 ext.1563 Fax:+886-3-5779058
e-mail:ctyang@nspo.gov.tw
Chao-Tung Yang *Chi-Chu Hung
Associate Researcher Satellite Analyst
Ground System Section
National Space Program Office
Hsinchu, Taiwan
Tel:+886-3-5784208 ext.1563 Fax:+886-3-5779058
e-mail:ctyang@nspo.gov.tw
Keywords: Parallel Computing, Clustering, Speedup, Remote Sensing
Abstract
There are a growing umber of people who want to use remotely sensed data and GIS data. What is needed is a large-scale processing and storage system that provides high bandwidth at low cost. Scalable computing clusters, ranging from a cluster of (homogeneous or heterogeneous) PCs or workstations, to SMPs, are rapidly becoming the standard platforms for high-performance and large-scale computing. To utilize the resources of a parallel computer, a problem had to be algorithmically expressed as comprising a set of concurrently executing sub-problems or tasks. To utilize the parallelism of cluster of SMPs, we present the basic programming techniques by using PVM to implement a message-passing program. The matrix multiplication a d parallel ray tracing problems are illustrated and the experiments are also demonstrated on our Linux SMPs cluster. The experimental results show that our Linux/PVM cluster can achieve high speedups for applications.
1 Introduction
There are a growing umber of people who want to use remotely sensed data and GIS data. The different applications that they want to required increasing amounts of spatial, temporal, and spectral resolution. Some users, for example, are satisfied with a single image a day, while others require many images a hour. The ROCSAT-2 is the second space program initiated by National Space Program Once (NSPO) of National Science Council (NSC), the Republic of China. The ROCSAT-2 Satellite is a three-axis stabilized satellite to be launched by a small expendable launch vehicle into a sun-synchronous orbit. The primary goals of this mission are remote sensing applications for natural disaster evaluation, agriculture application, urban planning, environmental monitoring, and ocean surveillance over Taiwan area and its surrounding oceans.
The Image Processing System (IPS) refers to the Contractor-furnished hardware and software that provide the full capabilities for the reception, archival, cataloging, user query, and processing of the remote sensing image data. The IPS will be used to receive, process, and archive the bit sync remote sensing image data from the X-band Antenna System (XAS) of NSPO. The XAS is dedicated for receiving the high-rate link of the earth remote se sing data from ROCSAT-2 satellite, and has the capability of receiving down link data rate up to 320Mbps. It will also be expanded to receive data from other remote sensing satellites. Generally, IPS has configuration to receive satellite data like that depicted in Figure 1.Remote sensing data comes to the IPS via either a satellite link or some other high-speed network and is placed in to mass storage. Users can the process the data through some of interface.
What is needed is a large-scale processing and storage system that provides high bandwidth at low cost. Scalable distributed memory systems and massively parallel processors generally do not fit the latter criterion. A cluster is type of parallel and distributed processing system, which consists of a collection of interconnected stand-alone computers working together as a single, integrated computing resource [1,2,3] .A computer ode can be a single or multiprocessor system (PCs, workstations, or (SMPs) with memory, I/O facilities, and a operating system. A cluster generally refers to two or more computers (nodes) connected together. The nodes can exist if a single cabinet or be physical separated and connected via a LAN. A interconnected (LAN-based) cluster of computers can appear as a single system to users a d applications. Cluster nodes work collectively as a single computing resource and fill the conventional role of using each node as a independent machine. A cluster computing system is a compromise between a massively parallel processing system and a distributed system. A MPP system node typically cannot serve as a standalone
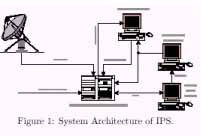
Figure 1: System Architecture of IPS
I recent years, the performance of commodity-off-the-shelf (COTS) components, such as processor, memory, hard disk, and networking technology, has improved tremendously. Free operating systems, such as Linux and Free-BSD, are available and well supported. Several industry-standard parallel programming environments, such as PVM [ 5 ] ,MPI, and Open MP, are also available for, and are well-suited to, building clusters at considerably lower costs. Such a system can provide a cost-effective way to gain features and benefits (fast and reliable services) that have historically been found only no more expensive proprietary shared memory systems. The main attractiveness of such system is that they are built using affordable, low-cost, commodity hardware (such as Pentium PCs), fast LAN such as Myrinet, and standard software computers such as MPI, and PVM parallel programming environments. These systems are scalable, i.e., they can be tuned to available budget and computational needs and allow efficient execution of both demanding sequential and parallel applications.
RSS (Ground System Section) currently operates and maintains an experimental Linux SMP cluster (SMP PC machines running the Linux operating system) which is available as a computing resource for test users [ 6 ] . The Ground ' s Linux SMP cluster (LSC) machines are operated as a unit, sharing networking file servers, and other peripherals. This cluster is used to run both serial and parallel jobs. I this paper, an experimental environment for remote sensing and telemetry application development on a cluster is proposed. The cluster would provide a mechanism for the scientist or engineer to utilize high-performance computer systems without requiring extensive programming knowledge [ 7 ] .
As the growing volume of satellite data increases with the growing umber of users who want to process the data, there is a need to move away from the traditional computer to more powerful supercomputers. The cost, however, of these computers generally places a constraint o the types of users. Clusters of parallel computers provide a good ratio of cost-to-performance and it is within this framework that we design LSC.LSC is aimed at making it easy to process large amounts of satellite data quickly. This is accomplished through an environment tailed towards design of parallel component-based software that can easily be connected and gain high-performance.
2 An Example: Matrix Multiplication
The most commonly used program as shown in Figure 2 in parallel processing has a uniform workload. Since matrix a rows and matrix b columns are referenced constantly, and the elements of both matrices are not modified, a local cache if available will be very useful to the system. This algorithm requires n3 multiplications and n3 additions, leading to a sequential time complexity of O(n3).
for (i = 0; i < N; i ++ ) /* can be parallel zed */
for (j = 0; j < M; j++ ){ /* can be parallel zed */
c[i] [j] = 0;
for (k = 0; k < P; k++)
c[i] [j] = c[i] [j] + a[i] [k] * b [k] [j];
}
Figure 2: A kernel of Matrix Multiplication.
The serial program computes a result matrix result by multiplying two input matrices, a and b Matrix a consists of N rows by P columns and matrix b contains P rows by M columns. These sizes yield a result matrix c of N rows by M columns. The serial version of the program was quite straightforward.
Let ' s consider what we need to change in order to use PVM. The first activity is to partition the problem so each slave can work on its own assignment in parallel. For matrix multiplication, the smallest sensible unit of work is the computation of one element in the result matrix. It is possible to divide the work in to even smaller chunks, but any finer division would not be useful. For example, the umber of processor is not enough to process, i.e., n2 processors are needed.
The matrix multiplication algorithm is implemented in PVM using the master-slave paradigm. The master task is called master_mm_pvm, and the slave tasks are called slave_mm_pvm. The master reads in the input data, which includes the umber of slaves to be spawned, nTasks. After registering with PVM and receiving a taskid or tid it spawns nTasks instances of the slave program slave_mm_pvm and the distributes the input graph information to each of them. As a result of the spaw function, the master obtains the tids of each of the slaves.Since each slave needs to work on a distinct subset of the set of matrix elements, they need to be assigned instance IDs in the range (0,...,nTask -1). The tids assigned to them by the PVM library do not lie in this range, so the master needs to assigned the instance Ids to the slaves a d se d that information along with the input matrix. The slaves also need to know the total number of slaves in the program, and this information is passed o to them by the master process as an argument to the spaw function since, unlike the instance IDs, this umber is the same for all nTasks slaves.
To send the input data and instance ID information, the master process packs these into the active send buffer, and the invokes the send function. It the waits to receive partial results from each of the slaves. The slaves register with the PVM environment, and the wait for input data from the master, using a wildcard in the receive function to receive a message from any source. Once a message is received, each slave determines the master's tid from the received message buffer properties. Alternatively, the slaves could have determined the master ' s tid by calling the pvm parent() function, which they could have used as the source in their receive function. On receiving the message from the master that contains the input matrix, a slave unpacks this data from the active receive buffer. Each slave the works on its input partition, and send its partial results to the master when it is done. The the master collects these partial results into a output matrix and outputs the results.
I the slave program, we keep the basic structure of the sequential program intact. But now the routine to multiply the two matrices, the main program of slave mm_pvm does not do the actual work itself, only performs the loop partition for each individual portion. In stead, the slave program calls a function matrix multiple to perform real matrix multiplication. The individual slaves each then perform a portion of the matrix multiplication as shown in Figure 3.
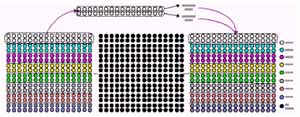
Figure 3:The block version of partitioning.
Our SMP cluster is show in Figure 4 that consists of nine PC-based multiprocessors connected by a switched Hub with Fast Ethernet interface. There are one server node a d eight computing nodes. The server node has two Intel Pentium-!!! 667MHz processors and 256MBytes of shared local memory. Each computing node has two Celeron processors and 196MBytes of shared local memory. Each Pentium-!!! has 32K on-chip instruction and data caches (L1 cache), a 256K on-chip four-way second-level cache with full speed of CPU. Each Celeron also has 32K on-chip instruction a d data caches (L1 cache), a 128K on-chip four-way second-level cache with full speed of CPU. The individual processors are rated at 495MHz, and the system bus has a clock rate of 110 MHz.

Figure 4: The snapshot of SMP-based cluster.
3.1 Matrix Multiplication Results
The matrix multiplication was run with forking of different umbers of tasks to demonstrate the speedup. The problem sizes were 256X256, 512X512, 768 X768, 1024X1024, and 1280X1280 in our experiments. It is well known, the speedup can be defined as ts / tp, where ts is the execution time using serial program, and tp is the execution time using multiprocessor. The execution time o dual2 (2 CPUs),dual2 ~3 (4 CPUs),dual2 ~4 (6 CPUs),dual2 ~5(8CPUs), and dual2 ~9 (16 CPUs), were listed in Figure 5, respectively.The corresponding speedup of different problem size by varying the umber of slave programs were shown in Figure 6.Since matrix multiplication was uniform workload application, the highest speedup was obtained about 10.89 (1280 ?1280)by using our SMP cluster with 16 processors. We also found that the speedups were closed when creating two slave programs o one dual processor machine a d two slaves program on two SMPs respectively.
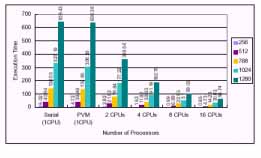
Figure 5: Execution time (sec.) of SMP cluster with different number of tasks (slave programs).
Pov-ray is a multi-platform, freeware ray tracer [4]. Many people have modified its source code to produce special "unofficial" versions. One of these unofficial versions is PVMPOV, which enables POVray to run o a Linux cluster.
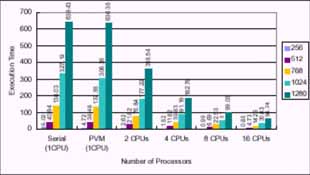
Figure 6: Speedup of SMP cluster with different number of tasks (slave programs).
./pvmpov +iskyvase.pov +w640 +h480 +FT +v1 -x -d +a0.300 -q9 -mv2.0 -b1000
-nw32 -nh32 -nt4 -L/home/gs17/pvmpov3\_1e\_1/povray31/include
This is the benchmark option command-line with the exception of the -nw and -nh switches, which are specific to PVMPOV and define the size of image each of the slaves will be working o .The -nt switch is specific to the umber of tasks will be running. For example, -nt4 will start four tasks, one for each machine. The messages on the screen should show that slaves were successfully started. When completed, PVMPOV will display the slave statistics as well as the total render time. Using single processor mode of a dual processor machine for processing 1600 X1280 image, the render time was 369 seconds. Using both CPU ' s o a single machine reduced the render time to 190 seconds. Adding the second machine with dual CPU ' s dropped the time to 99 seconds. Using out SMP cluster (16 processors) further reduced the time to 27 seconds. The execution time o dual2, dual2 ~3, dual2 ~4, dual2 ~5, and dual2 ~9, were show in Figure 8, respectively. The corresponding speedup of different problem size by varying the umber of task (option:-t) were show in Figure 9. The high speedup were gained about 1.94 (1600X1280) on dual2, and 3.73 (1600 ?1280) using both dual2 and dual3.The highest speedup was obtained about 13.67 (1600 X1280)by using our SMP cluster with 16 processors.

Figure 7: The skyvase.tga genreated form PVMPOV.
Scalable computing clusters, ranging from a cluster of (homogeneous or heterogeneous) PCs or workstations, to SMPs, are rapidly becoming the standard platforms for high-performance and large-scale computing. It is believed
that message-passing programming is the most obvious approach to help programmer to take advantage of clustering
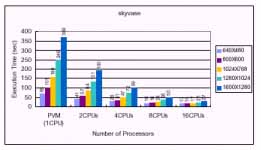
Figure 8: Execution time (sec.) of SMP cluster with different number of tasks (slave programs).
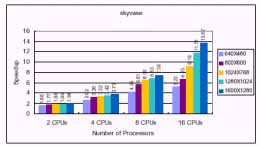
Figure 9: Speedup of SMP cluster with different number of tasks.
References
- R.Buyya,High Performance Cluster Computing: System and Architectures Vol.1,Prentice Hall PTR,NJ,1999.
- R.Buyya,High Performance Cluster Computing: Programming and Applications Vol.2,Pre ticeHallPTR,NJ, 1999.
- G.F.P . ster,In Search of Clusters Prentice Hall PTR,NJ,1998.
- http://www.haveland.com/povbench/,POVBENCH - The O . cial Home Page.
- http://www.epm.ornl.gov/pvm/,PVM - Parallel Virtual Machine.
- T.L.Sterling,J.Salmon,D.J.Backer,and D.F.Savarese,How to Build a Beowulf: A Guide to the Implementation and Application of PC Clusters 2 d Printi g,MIT Press,Cambridge,Massachusetts,USA,1999.
- B.Wilkinson a d M.Allen,Parallel Programming: Techniques and Applications Using Networked Workstations and Parallel Computers Prentice Hall PTR,NJ,1999.