| GISdevelopment.net ---> AARS ---> ACRS 1991 ---> Poster Session |
Automatic determination of
categories in unsupervised classification
Sunpyo Hong, Kiyonari
Fukue, Haruhisa Shimoda. Toshibumi Sakata
Tokai University Research and Information Center
2.28-4 Tomigaya, Shibuya – ku. Tokyon 151, Japan
Tokai University Research and Information Center
2.28-4 Tomigaya, Shibuya – ku. Tokyon 151, Japan
Abstract
A cluster categorization method is necessary when an unsupervised classification is used for remote sensing image classification. It is desirable that this method is performed automatically, because manual categorization is a highly time consuming process.
In this paper, several automatic determination methods were proposed and evaluated. They ar4e 1) maximum number method. which assigns the target cluster to the category which occupies the largest area of that cluster: 2) maximum percentage method, which assigns the target cluster to the category which shows the maximum percentage within the category in that cluster : 3) minimum distance method, which assigns the target cluster to the category having minimum distance with that cluster. From the results of experiments, it was certified that the result by the minimum distance method was almost the same as the result made by a human operator.
Introduction
With the launch of second generation high resolution sensors like LANDSAT TM and SPOT HRV. clustering method has been revaluated recently. However, the main problem of clustering for practical use is that clustering is an unsupervised classification. That is , clusters generated by clustering are defined in feature vector space, not in image data. Therefore, in order to use that classified result for a; meaningful reference map, it is necessary to determine the relation of clusters and categories, and to label the classified result with the categories.
Conventionally, this relation have been determined mainly by interpretation of an operator. However, this process is time consuming and is not objective.
The purpose of this research is to try several methods of automatic cauterization and find and find out the most useful method. In this paper, 3 methods have been examined.
Problems of conventional Method
In this method, each classified cluster is overlaid with the target image data on the display, and that cluster is interpreted by an operator to determine the category, and that cluster is interpreted by that the obtained result is natural and reliable.
However, since everything is determined by an operator in this method, there many problems as follows.
- The result depends on the skill of an operator.
- Objective and quantitative evaluation is difficult.
- It is time consuming when the number of class is large or there are many small clusters.
To solve the above problems, several automatic categorization methods are considered as follows. In all methods, training areas are first extracted from the image similar to supervised trainings.
1- Maximum Number Method
In this method, the number of pixels in each category for each cluster is calculated, Then the category having the maximum number is assigned to that cluster.
2- Maximum Percentage of Category Method.
In this method, for each cluster, the percentage ( occupation rate ) of that cluster in each category is calculated. Then the category having the maximum percentage is assigned to that cluster,
Fig. 1 shows a comparison of these two methods in a simple case. Suppose that cluster k is compose of three categories A, B and C. As shown in Fig. 1 (a) , category A occupies ;the largest area in class k and C occupies the minimum area. In the maximum number method, cluster is always assigned to category A. However, this figure does not show the difference of areas of each category . Fig. 1 (b) shows the case the difference of areas of each category . Fig. 1 (b) shows the case that the total area of each category is the same and (c) shows the case that the total area of each category is different. As shown from this figure, categories which occupy small areas in the image tends to be neglected in the maximum number method. On the contrary, small area categories are tread favorably in the maximum percentage method as shown in Fig. 1.
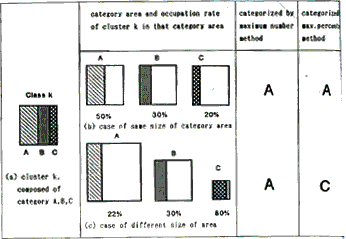
Fig. 1 Cluster and Categories
3. Minimum Distance Method
In this method, the distance between each category and each cluster is calculated. Then the category having the minimum distance is assigned to that cluster. Euclidian distance was used in this experiment.
In the case of the maximum number method and the maxima, percentage method, the result is dependent upon the size and location of training areas. In the minimum distance method, training areas selection is easier than other 2 methods, because the geometrical information of the training area is not used.
Experiments and Results
1 Flow of Experiments
In order to evaluate the proposed methods described in chapter 3, following LANDSAT TM data was used in the experiment.
At first, clusters were generated by a hierchical cluster mint using Ward method. Since the image data in remote sensing is very large, usually clustering is performed with sampled data. In this experiment, 2500 samples (about 10% of entire image data) were used to generate 66 clusters. Based on the 66 clusters, the target image data was classified by a maximum likelihood method. Secondly, representative area of each category in the target image (training area) was selected. 14 categories were selected as shown in Table 1. Finally, the relations of clusters with categories were determined by 3 methods described in chapter 3.
| Categories | Clusters | |||||
| Major | Test site category | Selected category | Supervised | Number | Percent. | Dist. |
| TREE | Coniferous tree,broad leaved tree, mixed tree, bamboo orchard, etc, | Coniferous treebroad leaved tree mixed tree shadow | 3 5 3 2 |
7 4 3 2 |
5 4 5 2 |
4 3 7 2 |
| PADDY | Paddy | Paddy 9 | 11 | 10 | 8 | |
| CITY | Concrete, factory,building, railway, house, urban etc | Urban area house are factory | 4 6 5 |
4 11 8 |
2 13 8 |
3 11 7 |
| WATER | Sea, river,Pool, pond | SeaRiver | 2 2 |
2 1 |
2 1 |
2 2 |
| OTHER | Farm, vinyl house,Ground, grassland, Lawn, gravel, sand,Ordered land, etc | FarmGrass landGroundSand area | 6 5 6 1 |
6 4 3 0 |
6 4 3 1 |
6 3 8 0 |
| 5 | 44 | 14 | 59 | 66 | 66 | 66 |
To evaluate quantitatively. classification accuracy ws estimated basd on the test site data in target image. the classification accuracy was calculated over 5 major categories as shown in table 1 to adjust the selected categories in target image and the test site categories.
2. Results of Experiments
- Conventional Supervised Classification Method
For the purpose of comparison, a supervised maximum likelihoos method was executed. in this method tainting data was extracted by 1 human operator with ground truth. and the extracted training data was 59 classes as shown in Table 1. With this training data, maximum likelihood classification was performed, and the classificed result was labeled with 14 categories (Table 1) as shown in Fig. 2. Table 2 shown the classification accuracy by this method with the test site area.

Fig. 2 Result by Supervised Method
Table 2 Classification Accuracy by Supervise Method
TREE PADDY CITY WATER OTHER TREE 44.06 2.19 24.55 3.16 26.04 PADDY .80 63.71 12.25 .71 22.52 CITY 4.50 2.49 81.63 1.79 9.59 WATER 6.15 1.36 22.18 61.92 8.40 OTHER 10.84 9.52 36.77 3.16 39.71 Area weighted mean: 64.35 Arithmetic mean: 58.20
- Maximum Number Method
Fig. 3 shows the results by this method, and Table 3 shows the classification accuracy estimated with the test site data. As expected, this result shows the tendency that classes were labeled with the categories having large areas.

Fig. 3 Result by Maximum Number Mehtod
Table 3 Classification Accuracy by Maximum number Method
TREE PADDY CITY WATER OTHER TREE 55.94 2.37 32.31 .04 9.34 PADDY 2.25 58.32 12.43 .00 27.00 CITY 6.13 3.12 84.35 .07 6.34 WATER 9.52 1.89 32.53 51.74 4.32 OTHER 22.59 10.55 39.84 .46 26.57 Area weighted mean: 64.74 Arithmetic mean: 55.38
- Maximum Percentage Method
Fig. 4 shows the result by this method, and Table 4 shows the classification accuracy estimated with the test site data. As expected, this result shows the tendency that classes were labeled with the categories having small areas.

Fig. 4 Result by Maximum Percentage Mehtod
Table 4 Classification Accuracy by Maximum percentage Method
TREE PADDY CITY WATER OTHER TREE 48.14 2.37 30.51 .04 18.94 PADDY 1.97 61.68 12.37 .00 23.97 CITY 5.51 3.14 75.94 .07 15.34 WATER 8.52 1.89 32.17 51.74 5.68 OTHER 15.93 11.07 36.97 .46 35.58 Area weighted mean: 59.98 Arithmetic mean: 54.61
- Minimum Distance Method
Fig. 5 shows the result by this method, and Table 5 shows the classification accuracy estimated with the test site data. This result is very similar to the result (fig. 2) by a human operator using maximum likelihood classification method. In order words, a good result was obtained with roughly selected training area.

Fig. 5 Result by Minimum Distance Method
Conclusions
- In the case of the maximum number method, the classes are hardly labeled with the small area categories. on the contrary, in the case of the maximum percentage method. the classes are hardly labeled with large area categories. These are general problems for these two methods, because usually the area of each category is not the same.
- In the case of the minimum distance method. almost the same result with a supervised classification was obtained. This method also needs less number of pixels for training area compared to other 2 methods.
- The classification accuracies were the maximum for the minimum distance method, second, the maximum number method and the minimum for the maximum percentage method. The difference of area weighted mean classification accuracy with the minimum distance method and the classification accuracy with the minimum distance method and the maximum percentage method was about 3.5%. The difference of area weighted mean classification accuracy with the minimum distance method and the supervised classification method was about 1%.
- From the view point of practical use, the maximum number method and the maximum percentage method are easy to execute because they need less number of categories, but the classification accuracy of both methods is lower than that of the minimum distance method.
- Among the methods which were evaluated, the minimum distance method showed best result. in this method, obtained result is almost the same with a supervised maximum likelihood classification method, but it needs more number of categories than the maximum number method and the maximum percentage method. However, this method has a merit that the training area can be roughly selected.